-
Fast Speech 2 ReviewPapers 2022. 7. 26. 14:18
Key Point
- ground truth target에 대해서 모델을 직접 학습시킨다.
(텍스트로부터 음성을 직접 생성하고 병렬적으로 처리함) - pitch, energy, duration 같은 다양한 정보들을 도입하고 조건부로 입력 받아 음성을 생성한다.
(여러 모듈들을 사용해서 위의 information을 추출하고 조건부로 사용) - Fastspeech 1 모델보다 학습속도와 추론 속도가 빠르다. 음성 품질을 개선했다.
(Fastspeech 2s 모델에서는 멜스펙토그램을 사용하지 않는다.)
1. Motivation
왜 Fastspeech 2 모델이 나왔을까요?
TTS는 one-to-many mapping 문제입니다. 왜냐하면 하나의 단어에 대해서 매우 많은 경우의 수에 대한 음성이 대응되기 때문입니다. '안녕하세요' 라는 텍스트는 성별, 나이, 감정, 억양, 목소리 크기에 따라 다양하게 발음될 수 있습니다. STT 문제와는 달리 문제가 훨씬 더 어려워진 것입니다. 기존의 non-autoregressive TTS 방식에서는 오직 텍스트 입력만을 사용해서 음성을 생성했습니다. 이 경우, target에 오버피팅 될 가능성이 높고, 새로운 텍스트에 대한 음성의 품질이 떨어질 수 있습니다. Fastspeech 2는 기존 모델의 1) one-to-may mapping 문제, 2) target mel-spectrogram의 정보손실 문제, 3) 부정확한 duration 예측 문제를 해결합니다.
이제 기존의 Fastspeech 1 단점을 확인하기 위해 모델 그림을 잠시 살펴보겠습니다.

그림1: Fastspeech 1 Architecture - 기존의 Fastspeech 1 같은 모델은 Feed-Forward Transformer를 사용해서 non-autoregressive하게 음성을 생성하고 autoregressive 계열 모델들보다 빠르게 출력을 생성할 수 있었습니다. (a), (b)
- 텍스트를 음성으로 바꾸는 과정에서 음성의 지속시간을 조절하기 위해 duration predictor 같은 모듈들이 존재해야 했습니다. teacher 모델의 attention map으로부터 추출된 duration이 부정확했습니다. (d)
- Fastspeech 1 모델에서는 위의 teacher 모델에 의존하여 knowledge distillation을 하는 방식으로 모델을 학습시켰는데 이는 학습과정을 복잡하게 만들었습니다. teacher 모델과 duration predictor로부터 생성된 target mel-spectrogram들 $\cal H_{mel}$이 정확하지 않고 정보가 손실되었습니다. (c)
2. Methods (Architecture)
그렇다면 이제 Fastspeech 2 모델이 어떤 방법으로 Fastspeech 1을 개선했는지 알아보겠습니다.

그림2: Fastspeech2 Architecture Summary
모델의 특징은 다음과 같습니다.
- Encoder의 구조는 Fastspeech 1의 Feed-forward Transformer를 사용합니다. (그림 1의 a, b) 이는 몇 개의 self attention layer를 쌓고 1D-Convolution을 통해 구성합니다.
- Fastspeech 1의 teacher-student distillation pipeline을 제거했습니다.
- Variance adaptor을 도입해서 다양한 정보들이 hidden vector에 녹아들도록 만들었습니다.
- Fastspeech 2s를 도입해서 mel-spectrogram 생성과 vocoder 없이 텍스트로부터 waveform을 직접 생성합니다. (그림 2의 a 점선 상자)
2.1 Feed-forward
그림 2 (a)의 전체적인 feed-forward 연산과정은 다음과 같습니다.
- 음소 시퀀스를 입력 받아서 Phoneme Embedding Layer를 통과 시킨 후 벡터를 얻는다.
- 임베딩 벡터를 positional encoding된 벡터와 concat하여 Encoder에 입력시킨 후 벡터를 얻는다.
- Encoder의 output 벡터를 Variance Adaptor를 통과시켜 다양한 정보(Pitch, Energy, Duration)가 포함된 hidden 벡터를 얻는다.
- 다시 Positional encoding된 벡터와 concat해서 Mel-spectogram Decoder, Waveform Decoder에 입력한다. (이때, 병렬적으로 처리한다.)
- 최종적으로 Mel-spectorgram과 Waveform을 얻는다.
2.1 Variance Adaptor
variance adaptor의 목표는 duration, pitch, energy 같은 다양한 정보들을 hidden phoneme sequence에 추가하는 것입니다. 이 방식으로 one-to-many mapping 문제를 어느 정도 완화할 수 있게 됩니다. (저의 사견으로는 다른 정보들을 추가해주므로domain space의 크기는 늘어나고 codomain의 space 크기는 줄어서 가능한 mapping의 수를 줄인다고 생각했습니다.) 논문에서는 다음과 같이 세 가지 정보들을 도입했습니다.
- phoneme duration: 음소의 지속시간
- pitch: 소리의 높이 (진동수)
- energy: 소리의 크기 (진폭)
저자는 추후의 연구에 화자의 speech style이나 emotion을 넣을 수 있는 방법도 가능하다고 말합니다. 위의 정보들을 추출하는 각각의 predictor들이 존재하고 모델 구조를 공유하지만 다른 파라미터를 사용한다고 합니다. (그림2 c)
Duration predictor: 기존의 pre-trained autoregressive TTS 모델에서 추출하는 방식 대신 Montreal forced alignment를 사용했습니다.
Pitch predictor: Continuous wavelet transform을 사용해서 continuous pitch series를 pitch spectrogram으로 분해해서 pitch를 추출합니다. 자세한 내용은 Appendix D에서 확인할 수 있습니다.
Energy predictor: STFT 프레임의 각 진폭의 L2 Norm을 계산해서 energy로 사용합니다. 각 프레임은 256 개의 값을 가질 수 있도록 quantization합니다.
2.2 Fastspeech 2S
완전한 End-to-end waveform 생성을 위해서 Fastspeech 2s로 모델을 확장시켰습니다. acoustic model이나 vocoder없이도 text로부터 waveform을 생성합니다. 이 때, 두 가지 도전과제들이 있는데 논문에서는 이를 해결하는 방법을 제안합니다.
- waveform은 mel-spectrogram보다 더 많은 variance 정보를 가지고 있어서 입력과 출력 사이의 정보 차이가 더 큽니다.
- full text sequence에 대한 오디오 클립을 학습시키기 어렵습니다. 왜냐하면 긴 waveform 샘플들은 GPU 메모리를 많이 사용하기 때문입니다. 따라서 긴 텍스트를 나누어서 부분적으로 학습시키는 방법을 사용합니다. 그러나 이것이 텍스트들 간의 관계를 포착하기 어렵게 하기에 텍스트의 특징 추출을 잘 못하게 됩니다.
위의 문제들을 해결하기 위해 WaveNet 구조 기반의 디코더를 도입합니다. variance predictor를 사용해서 phase information을 예측하기는 어려운데요 그래서. waveform 디코더를 학습과정 중에 Adversarial training을 수행하고 디코더 그 자체가 phase information을 다루도록 만들었습니다. 기본적으로 네트워크는 non-causal convolution과 gated activation으로 블록이 구성됩니다. (그림 2 d)
학습과정은 다음과 같습니다.
- Waveform 디코더에 슬라이스된 은닉시퀀스를 입력합니다. 이는 짧은 오디오 클립에 해당합니다.
- 은닉 시퀀스를 1D transposed convolution을 통해 upsampling 해서 오디오 클립과 길이를 맞춥니다.
- Discriminator를 학습하는 과정은 Parallel WaveGAN과 동일한 구조를 채택합니다.
- 최종적으로 디코더는 multi-resolution STFT loss와 LSGAN discriminator loss를 통해 최적화됩니다.
- 추론 단계에서 멜스펙트로그램 디코더는 무시하고 waveform 디코더만 사용해서 음성을 생성하게 됩니다.
3. Experiments
논문에서 실험은 LJSpeech 데이터셋에 대해서 진행합니다. LJSpeech 데이터셋은 13100 개의 오디오 클립들 (약 24시간)과 텍스트 기록으로 구성됩니다. 데이터셋을 12228 개의 샘플을 학습에 사용하고 349개는 validation, 523개는 테스트에 사용합니다. 오발음 문제를 완하하기 위해 텍스트 시퀀스를 음소시퀀스로 전처리해서 사용했습니다. (grapheme-to-phoneme tool).

3.1 Model performance
20명의 원어민들이 평가를 시행했습니다. PWG는 parallel wavegan 모델입니다. GT (Mel + PWG)의 경우 원래의 Ground truth 음성을 멜스펙토그램으로 변환한다음 다시 PWG를 사용해서 되돌린 음성입니다. Fastspeech 2 (Mel + PWG)의 경우 멜스펙토그램을 PWG에 넣어서 음성을 생성했는데, 2s 모델보다 조금 더 좋은 성능을 보이고 있고, 기존의 Fastspeech 1보다 약간 성능이 개선되었습니다. 논문에서는 아래 표의 학습 시간과 추론 시간에 초점을 두고 있습니다.
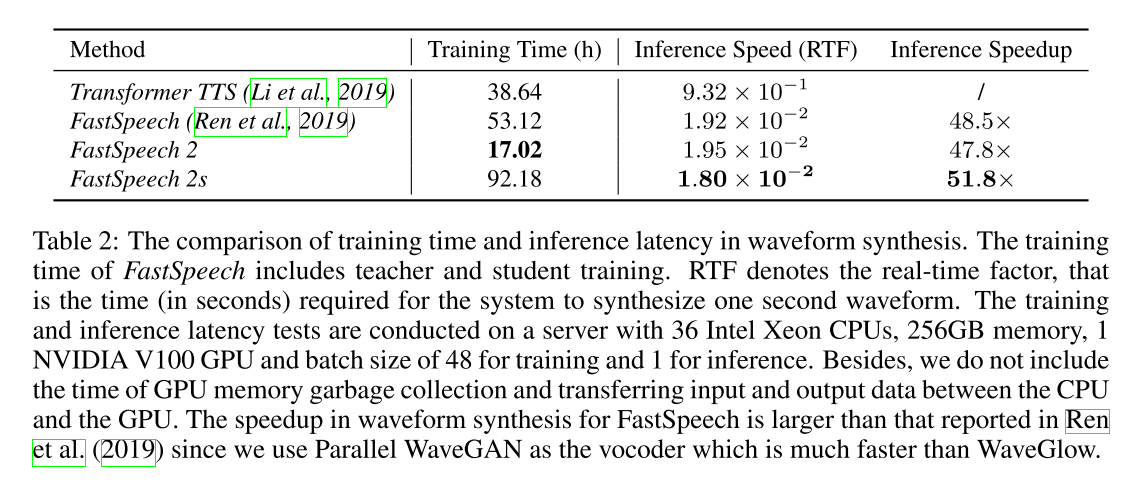
3.2 Training and Inference Speedup
학습시간을 보면 두 배 이상으로 빨라진 것을 볼 수 있고, 추론 속도도 Transformer TTS에 비해 굉장히 빠른 것을 확인할 수 있습니다. 다만 Fastspeech 2s의 경우 Vocoder 없이 동작하므로 학습이 굉장히 오래 걸리는 것으로 보입니다.
3.3 Analysis on Variance Information
1) Pitch

모델들이 생성한 음성의 Pitch에 대한 분석내용입니다. 비교를 위해 표준편차(standard deviation), 비대칭도(skewness), 첨도(kurtosis)를 계산했습니다. 그리고 average dynamic time warping distance를 계산했습니다. 이는 합성된 스피치와 실제 스피치의 pitch distribution의 거리를 계산한 것입니다. 표에서 Fast speech 2 모델이 Ground truth에 가까운 표준편차, 비대칭도, 첨도를 보입니다. 이는 모델이 실제와 비슷한 자연스로운 톤의 스피치를 생성할 수 있다는 것을 보입니다.
2) Energy

에너지에 대한 비교는 평균절대오차 (MAE)를 이용해서 비교했습니다. GT와 모델의 음성에서 프레임 단위로 추출된 에너지를 비교했습니다. Fastspeech 2의 경우 더 낮은 에너지를 보입니다. 즉, 실제와 더 비슷한 에너지를 가지는 음성을 생성합니다.
3) Duration

다음으로 duration predictor를 학습시키기 위해 제공된 duration 정보의 정확도를 분석했습니다. teacher model에서 생성된 50개의 오디오를 phoneme level로 구성된 텍스트와 ground truth phoneme을 직접 정렬했습니다. 그리고 FastSpeech의 teach model로부터 생성된 duration과 MFA로부터 생성된 duration을 사용해서 phoneme boundary 차이의 absolute average 값을 계산했습니다. 그리고 CMOS test라는 것을 수행해서 두 모델에서 생성된 음성의 품질을 비교했습니다. CMOS test는 두 개의 음성 데이터 쌍을 만들고, 비교를 통해 음성 품질을 평가하는 테스트입니다. 위 테이블에서는 MFA를 사용한 모델이 더 정확하게 duration을 예측하고 더 좋은 음성을 생성한다는 것을 보이고 있습니다.
3.4 Ablation Study
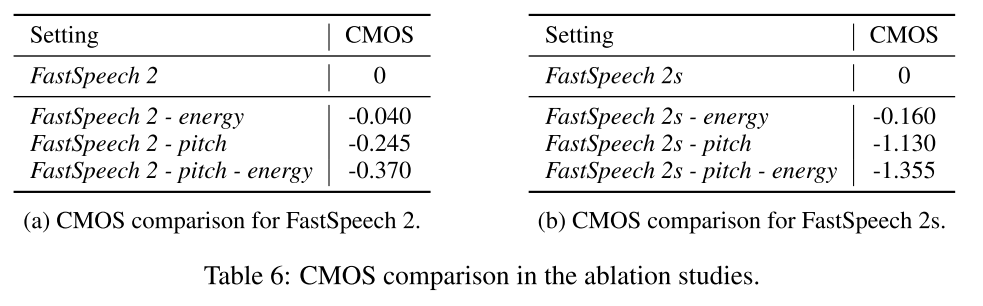
ablation study에서는 높이와 에너지 정보를 포함시키는 것의 효과를 보입니다. 에너지와 높이 정보를 포함하지 않은 모델은 CMOS test에서 점수가 낮아지는 것을 확인할 수 있습니다.
이상으로 논문 리뷰를 마치겠습니다. 다음 포스팅에서는 ESPnet이나 Speechbrain 라이브러리에서 Fastspeech 모델을 한국어 데이터에 직접 적용해보는 내용을 다룰 예정입니다 :)
References
[1] FastSpeech. Fast, Robust and Controllable Text to Speech
[2] FASTSPEECH 2. FAST AND HIGH-QUALITY END-TOEND TEXT TO SPEECH
- ground truth target에 대해서 모델을 직접 학습시킨다.