-
[Ray] - Introduction to RayProgramming 2022. 8. 18. 09:49
What is a Ray?
Ray는 파이썬을 위한 분산 강화학습 프레임워크입니다. 오픈소스이며 저수준 API를 통해 파이썬으로 작성된 프로그램을 쉽게 병렬처리할 수 있다. 고수준 API에서는 머신러닝을 모델을 위한 분산학습, 하이퍼파라미터 튜닝, 강화학습 알고리즘등을 제공하고 있습니다. 먼저 Ray를 설치해보겠습니다. 리눅스나 맥 환경에서 사용하는 것을 추천드립니다. (window는 베타버전)
pip install -U "ray[tune, rllib, serve]"이후, 주피터 노트북 파일을 만들어서 import하고 init 함수를 통해 ray를 실행시켜봅시다.
import ray ray.init()
Figure: Ray Dashboard 그러면 위와 같은 Dashboard를 띄울 수 있습니다. 현재 시스템에서 리소스를 얼마나 사용하고 있는지 확인할 수 있습니다.
What is a Ray cluster?
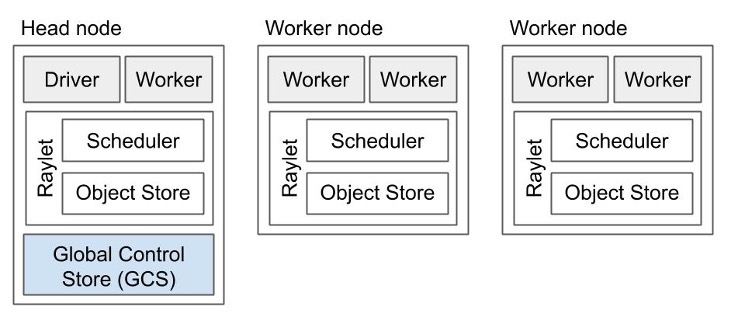
Figure: Ray Cluster 이제 본격적으로 Ray System의 구성요소들을 살펴보겠습니다. 우선 Ray cluster는 하나의 Head node와 여러 개의 Worker node 집합으로 구성됩니다. Head node 가 먼저 드라이버 프로세스와 함께 시작되고 클러스터 구성을 위해 주소값을 각 워커노드에 할당합니다. 각 Worker node은 할당된 작업을 수행하게 됩니다.
Ray cluster
- Head node
- Worker node
Worker node components
+ Worker process
+-- process 1
+-- process 2
+-- process n ...
+ Raylet
+-- Task Scheduler
+-- Object Store

Figure: Worker node Worker process, Raylet
Worker node는 그림처럼 여러 개의 Worker 프로세스들로 구성되어 있습니다. 각 worker unique한 ID와 IP 주소를 가집니다. worker 입력이 들어오면 판단하지 않고 실행합니다. 그렇다면 worker가 이미 많은 양의 작업을 처리하고 있거나 리소스가 부족하다는 것을 어떻게 알까요? Worker node 내부의 Raylet 컴포넌트가 이러한 정보들을 알려줍니다. Raylet은 노드의 컴포넌트 중에서 worker 프로세스를 관리합니다. Raylet의 구성요소는 그림처럼 Task scheduler와 Object Store로 구성됩니다.
Object store
모든 노드에는 object store가 존재합니다. 그리고 모든 object들은 분산된 object store에 집합적으로 저장됩니다. 이제 오브젝트 저장소라고 부르겠습니다. 오브젝트 저장소는 '공유 메모리'를 가지고 있는데 노드들 사이 또는 노드 내부에서 데이터를 공유하는 역할을 담당합니다. 그래서 worker 프로세스들이 필요한 데이터에 쉽게 접근할 수 있습니다.
Task scheduler
작업 스케줄러는 리소스를 관리합니다. 예를 들어, 특정 작업이 4개의 CPU를 요구한다면, 스케줄러는 free worker process를 찾아내고 프로세스들이 리소스에 접근하게 해줍니다. 따라서 스케줄러는 CPU, RAM, GPU에 대한 정보를 알고 있어야 합니다. (Dashboard에 있는 정보들)
스케줄러가 신경써야할 또 다른 것은 dependency resolution입니다. 즉, 각 worker들이 작업 수행에 필요한 모든 입력 데이터를 가지고 있는지 보장하는 것이 필요합니다. 처음에 스케줄러는 오브젝트 저장소에서 데이터를 검색해서 local dependency를 해결합니다. 만약 필요한 데이터가 현재 노드의 오브젝트 저장소에 없다면 스케줄러는 다른 노드들과 통신하고 remote dependency들을 받아옵니다. 스케줄러가 작업에 대한 충분한 리소스를 확보하고, 모든 의존성을 해결하고, 작업을 수행할 worker를 찾았다면 작업을 실행단계로 스케줄링합니다.
Head node

Figure: Head node 헤드 노드는 worker node의 모든 구성요소에 driver process와 global control store (GCS) 가 추가된 형태입니다.
GCS는 키와 값의 쌍을 저장하고 redis로 구현되어 있습니다. 클러스터에 대한 global 정보를 담고 있습니다.
예를 들어 아래와 같은 정보들을 저장합니다.
- Raylet이 동작하고 있는지 여부
- 모든 actor들의 주소위치
- 큰 오브젝트들이 속한 테이블
- 오브젝트간의 의존성
Ray Core API
Ray에서 핵심적으로 사용되는 API들을 정리해보겠습니다.
API Call 설명 ray.init() Ray Cluster를 초기화합니다. 주소를 인자로 주면 존재하는 클러스터에 연결합니다. @ray.remote 함수를 task로 만들고 클래스를 Actor로 만듭니다. ray.put() Object store에 데이터를 넣습니다. ray.get() Object store에서 데이터를 가져옵니다. task나 actor에 의해 계산된 결과를 가져옵니다. 동기적으로 동작합니다. .remote() Ray cluster에 존재하는 actor 메소드를 실행하거나 task를 실행합니다. 비동기적으로 동작합니다. ray.wait() Object reference들의 리스트 2개를 반환합니다. 하나는 완료된 테스크들의 리스트이고 다른 하나는 끝나지 않은 테스크들에 대한 것입니다. 바로 예제를 통해 API를 사용해보겠습니다. 주피터 노트북에서 코드 작성을 권장드립니다.
# ex 2-1
우선 ray를 사용하지 않고 데이터베이스에 있는 아이템을 검색하는 예제입니다.
import time import ray ray.init() database = [ "Learning", "Ray", "Flexible", "Distributed", "Python", "for", "Data", "Science" ] # ex 2-1 def retrieve(item): #time.sleep(item / 10.) time.sleep(len(database[item]) / 10.0) return item, database[item] def print_runtime(input_data, start_time, decimals=2): print(f"Runtime: {time.time() - start_time:.{decimals}f} seconds, data:") print(*input_data, sep="\n") start = time.time() data = [retrieve(item) for item in range(8)] print_runtime(data, start)출력 결과 시간이 대략 5초정도 걸렸습니다.
Runtime: 5.01 seconds, data: (0, 'Learning') (1, 'Ray') (2, 'Flexible') (3, 'Distributed') (4, 'Python') (5, 'for') (6, 'Data') (7, 'Science')# ex 2-2: ray.remote
@ray.remote 데코레이터를 통해 아주 간단하게 파이썬 함수를 Ray의 task로 만들 수 있습니다.
코드를 작성하고 제대로 동작하는지 확인한다음, 데코레이터를 코드에 추가하기만 하면 됩니다.
@ray.remote # 데코레이터를 사용하면 파이썬 함수를 Ray task로 만들 수 있다. def retrieve_task(item): return retrieve(item) start = time.time() data_references = [retrieve_task.remote(item) for item in range(8)] data = ray.get(data_references) print_runtime(data, start, 2)Runtime: 1.22 seconds, data: (0, 'Learning') (1, 'Ray') (2, 'Flexible') (3, 'Distributed') (4, 'Python') (5, 'for') (6, 'Data') (7, 'Science')놀랍게도 시간이 약 4배 가까이 줄어들었습니다. 더 빠르게 작업을 처리할 수 있었던 이유는 함수의 실행을 비동기적으로, 병렬처리 했기 때문입니다.
# ex 2-3: Object store with put and get
현재 상황은 retrieve 함수가 database에 직접 접근할 수 있습니다. 그래서 remote function 또한 local Ray cluster에 접근하면서 동작하게 됩니다. 하지만 여러 개의 컴퓨터로 구성된 실제 cluster 환경에서는 이렇게 데이터베이스에 직접 접근해서 함수를 동작시킬 수 없습니다. 데이터베이스를 공유메모리에 올리는 것이 필요한 것이죠!
ray에서는 driver나 여러 개의 worker 사이에서 데이터를 쉽게 공유할 수 있도록 put과 get이라는 메소드를 만들었습니다.- ray.put(object):
ray의 put함수를 통해서는 Head node나 Worker node의 Objectstore에 Object 데이터를 넣고 Store에 대한 레퍼런스 주소 값을 받아올 수 있습니다. - ray.get(object_store_ref):
ray의 get함수를 통해 레퍼런스 주소값을 넣어서 원래 데이터를 가져올 수 있습니다. 이렇게 오브젝트 스토어에 데이터를 공유하면 오버헤드가 줄어듭니다.
database_object_ref = ray.put(database) @ray.remote def retrieve_task(item): obj_store_data = ray.get(database_object_ref) time.sleep(len(obj_store_data[item]) / 10.0) return item, obj_store_data[item] start = time.time() data_references = [retrieve_task.remote(item) for item in range(8)] data = ray.get(data_references) print_runtime(data, start, 2)Runtime: 1.13 seconds, data: (0, 'Learning') (1, 'Ray') (2, 'Flexible') (3, 'Distributed') (4, 'Python') (5, 'for') (6, 'Data') (7, 'Science')오버헤드 감소로 인해 걸린시간이 약간 줄어든 결과를 볼 수 있습니다.
# ex 2-4: ray.wait() Wait function for non-blocking calls

ray.wait()의 동작
예제 2-2처럼 ray.get(data_references)를 사용해서 결과에 접근하는 것을 blocking 이라고 부릅니다. 즉, 모든 결과가 끝날 때까지는 값을 출력하는 것이 막혀있는 것이죠. 이는 Head node의 driver process가 모든 결과들이 끝날 때 까지 기다린다는 의미입니다. 지금의 경우에는 큰 문제가 되지 않지만 각 데이터를 처리하는 시간이 몇 분씩 걸릴 수도 있습니다. 이 때, 저희는 driver process가 대기하기보다는 다른 task들에 대해서 자유롭게 동작하기를 바랍니다. 드라이버가 작업이나 데이터가 들어올 때마다 처리하는 것이죠!
또 한 가지 생각해봐야할 것은 데이터를 탐색하지 못한다면 데드락이 발생할 수 있습니다. 데이터베이스 연결에 데드락이 발생하면 드라이버 프로세스는 멈추게 되고 모든 아이템을 탐색할 수 없게 된다. 따라서 적절한 타임아웃을 추가해서 코드를 작성해야 합니다.start = time.time() data_references = [retrieve_task.remote(item) for item in range(8)] all_data = [] while len(data_references) > 0: finished, data_references = ray.wait(data_references, num_returns=2, timeout=7.0) data = ray.get(finished) print_runtime(data, start, 3) all_data.extend(data)ray.wait() 함수는 task에 대한 레퍼런스 값을 받아서 끝난 task에 대한 레퍼런스 값과 완료되지 않은 레퍼런스 값을 리턴합니다. 그리고 timeout 인자를 통해 시간을 설정할 수 있습니다.
start = time.time() data_references = [retrieve_task.remote(item) for item in range(8)] all_data = [] while len(data_references) > 0: finished, data_references = ray.wait(data_references, num_returns=2, timeout=7.0) data = ray.get(finished) print_runtime(data, start, 3) all_data.extend(data)Runtime: 0.311 seconds, data: (1, 'Ray') (5, 'for') Runtime: 0.610 seconds, data: (4, 'Python') (6, 'Data') Runtime: 0.806 seconds, data: (0, 'Learning') (7, 'Science') Runtime: 1.110 seconds, data: (2, 'Flexible') (3, 'Distributed')# ex2-5: Actor class
@ray.remote 데코레이터를 함수 말고 클래스에도 적용할 수 있습니다. 이때, remote가 적용된 class는 actor라고 부릅니다. 이렇게 하면 클러스터에서 현재 상태를 표현할 수 있는 코드를 구현할 수 있습니다.
@ray.remote class DataTracker: def __init__(self) -> None: self._counts = 0 def increment(self): self._counts += 1 def counts(self): return self._counts # 이 클래스는 데이터 개수를 추적한다. @ray.remote def retrieve_tracker_task(item, tracker): obj_store_data = ray.get(database_object_ref) time.sleep(item / 10.) tracker.increment.remote() return item, obj_store_data[item] tracker = DataTracker.remote() data_references = [retrieve_tracker_task.remote(item, tracker) for item in range(8)] print(ray.get(data_references)) print(ray.get(tracker.counts.remote())) print(ray.get(tracker._counts))[(0, 'Learning'), (1, 'Ray'), (2, 'Flexible'), (3, 'Distributed'), (4, 'Python'), (5, 'for'), (6, 'Data'), (7, 'Science')] 8여기까지 ray의 내용들을 살펴보았습니다.
References
Welcome to the Ray documentation — Ray 1.13.0
If you’re new to Ray, check out the getting started guide. You will learn how to install Ray, how to compute an example with the Ray Core API, and how to use each of Ray’s ML libraries. You will also understand where to go from there.
docs.ray.io
2. Learning ray, 2022