-
Frame Stack, Frame Skip 정리카테고리 없음 2021. 4. 3. 00:03
OpenAI의 gym환경을 사용하다보면
BreakoutDeterministic-v4와 같이 NoFrameskip과 같은 단어가 붙은 환경을 보신적이 있을 것입니다.
굉장히 헷갈리는 개념들인데요 이 개념들이 이미지를 입력으로 받는 환경에서 학습에 상당한 영향을 끼치기에 Stack과 Skip의 의미를 정리해보겠습니다.
1. Frame Stack
Frame stack은 이미지를 관측(Image Observation)으로 받는 환경에서 주로 사용되는 기술입니다. 단어 뜻 그대로 이미지를 쌓아서 인공신경망에 입력으로 주게 되는 것입니다. 물론 벡터 관측(Vector Ovservation)도 스택으로 쌓아서 입력으로 사용할 수 있습니다. 그렇다면 왜 프레임을 하나씩 인공신경망에 입력하는게 아니라 굳이 여러 개를 입력하게 되었을까요?
그 이유는 한 오브젝트의 움직임이나 속도가 중요한 요소인 환경이 존재하기 때문입니다. 강화학습이 제어(Control) 문제를 해결하기 위해 나온 이론인 만큼 어떤 물체의 '동작이나 속도'를 관측해야하는 환경이 매우 많습니다.
야구공을 피해야 하는 환경을 예로 들어보겠습니다.

그림 : 위, 아래로 움직여서 야구공을 피할 수 있는 로봇 환경 그림에서 로봇은 야구공의 위치를 보고 위, 아래로 움직여서 피해야합니다. 그런데 사진이 한 장뿐이면 로봇은 야구공이 앞으로 어디로 움직일지 예측할 수 없을 것입니다. 신경망이 공의 현재 위치만으로 로봇의 움직임을 예측해서 행동을 출력해야한다는 것입니다
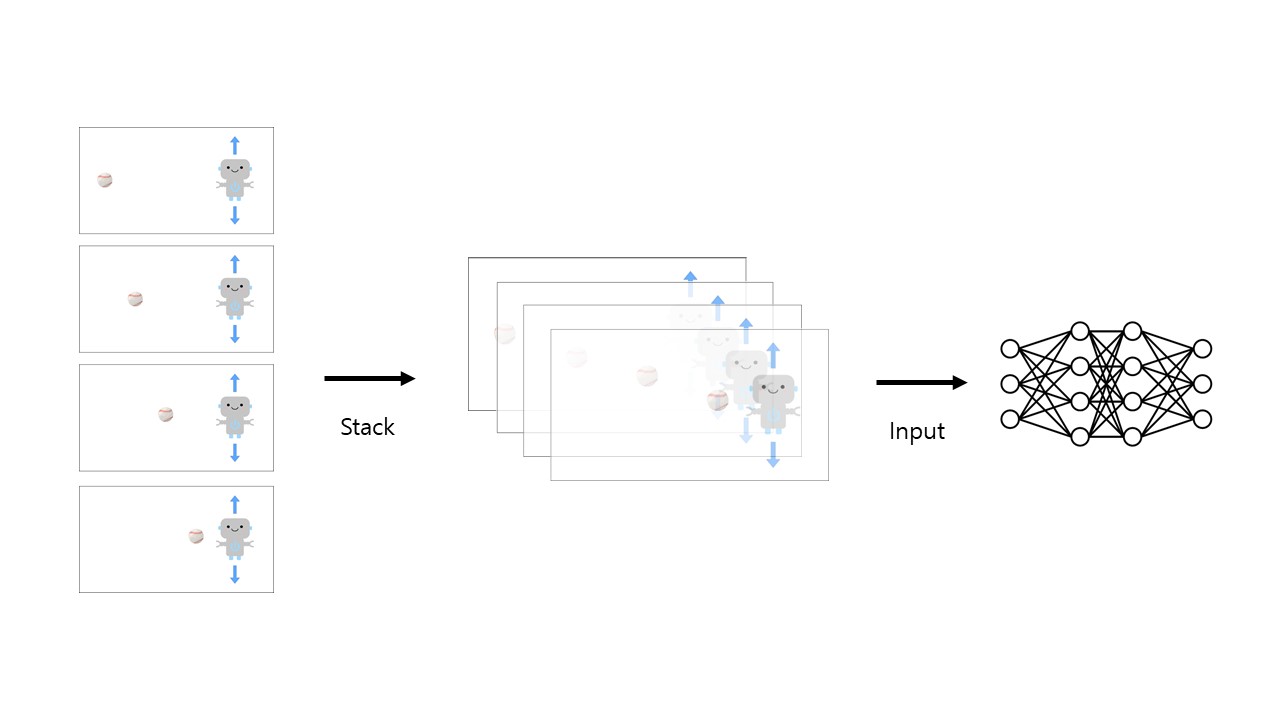
그림 : 이미지들을 쌓아서 신경망에 입력 즉, 로봇은 야구공을 피하기 위해 시간에 대한 현재 상태의 정보가 필요합니다. 위의 그림과 같이 네 개의 이미지 프레임을 쌓아서 신경망에 전달해주면 에이전트는 시간에 대한 야구공의 움직임을 받아들일 수 있게 됩니다. 이것이 바로 Frame Stack입니다. 크게 어렵지 않죠? 결과적으로는 4 Frame stack을 한다고 하면 (obs1, obs2, obs3, obs4) -> (obs2, obs3, obs4, obs5) -> (obs3, obs4, obs5, obs6). 이런 방식으로 모델에 이미지를 입력하게 됩니다.
2. Frame Skip
Frame skip은 에이전트의 관측(Observation)을 어떻게 처리할지 집중했던 Frame stack과 달리, 에이전트의 행동(Action)을 처리하는 기술입니다. Skip은 영어로에서건너 뛰다, 생략하다는 의미로 사용됩니다.
즉, Frame skip은 특정 개수의 이미지 프레임에 대한 행동을 건너뛴다는 의미입니다. 여러 이미지 프레임들 중에서 한 번 행동을 취하게 됩니다.
신경망에 대한 입력이 이미지 스택이 아닐 때, (매 번의 입력 이미지마다 행동을 출력해야할 때, 예를 들어, 4 frame을 skip하면 1, 2, 3번째 이미지에 대한 행동을 생략하고 마지막 이미지에 대해서만 행동을 출력할 수 있습니다.
여기서 중요한데요. 아타리 같은 게임을 학습한다고 했을 때, 게임 엔진 내의 프레임과 에이전트의 시간간격(timestep)이 1:1로 일치하지 않는 경우가 많습니다. 관측에 사용되는 프레임과 행동의 시간간격이 달라서 새로운 관측값(state prime)에 행동이 너무 빠르게 혹은 느리게 반영될 수 있습니다. 그래서 보통은 위에서 사용했던 Frame Stack을 통해 Skip할 프레임을 묶어서 에이전트의 시간간격과 대응시킵니다
그렇다면 신경망에 입력되는 이미지들에 대해서 행동을 어떻게 출력해야할까요? 만약 게임 엔진 내의 프레임과 타임스텝이 일치한다면 Frame Stack도 사용하지 않고 입력된 이미지마다 행동을 출력하는 것이 가장 정확한 방법일 것입니다. 대신 이 방법은, 위에서 언급했듯, 시간에 대한 객체의 정보가 신경망에 반영되지 않습니다. 그리고 이 방법은 모든 매 순간의 입력마다 행동가치 (Action Value)를 계산해야하므로 매우 계산량이 많아져서 비효율적일 것입니다.
따라서 행동을 처리하는 방법에 대해서 여러가지를 생각해볼 수 있습니다.
[1] 게임 내의 frame과 에이전트의 timestep이 대응되어서 Frame stack을 사용하지 않고 Frame skip을 사용할 경우
스킵되는 이미지들 중에서 하나의 이미지에 대한 출력값을 사용할 수 있습니다. 예를 들어 4개의 프레임을 스킵한다고 했을 때, 4개의 이미지 중 하나를 에이전트 관측값으로 입력해서 그에 대한 행동 가치를 사용하는 것입니다. 이때, 네 개의 timestep 모두에 대해서 같은 행동을 취하는 방법, 하나의 timestep에 대해서만 행동을 취하는 방법이 있습니다.
이것에 대한 예시로는 mlagent의 decision requester가 있습니다.
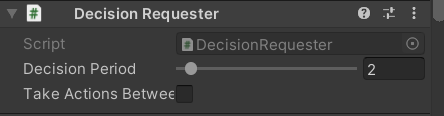
그림 : mlagent의 Decision Requester 컴포넌트 그림에서 Decision Period는 몇 번의 관측마다 행동을 할 것인지를 결정합니다. 값을 1로 정하면 매 번의 관측마다 행동을 하게 되므로 Noframeskip이 됩니다. Period 값을 2 이상으로 하면 이때, 각 Period 들에 대해서 행동을 할 지 말지를 결정할 수 있는데 체크를 하면 모든 timestep에 대해 행동을 하고 체크를 비우면 Period 값마다 행동을 취하게 됩니다.
[2] Frame stack을 사용하고 Frame skip을 사용할 경우 : 추가 예정
이제 마지막으로 Frame stack을 사용했을 때를 생각해보겠습니다.
모방학습(Imitation Learning)에서 Frame stack과 Frame skip의 중요성 기록 예정
참조 :
[1]. www.reddit.com/r/reinforcementlearning/comments/fucovf/confused_about_frame_skipping_in_dqn/
Confused about frame skipping in DQN.
I was going through the DQN paper from 2015 and was thinking I'd try to reproduce the work (for my own learning). The authors have mentioned that...
www.reddit.com
Frame Skipping and Pre-Processing for Deep Q-Networks on Atari 2600 Games
For at least a year, I’ve been a huge fan of the Deep Q-Network algorithm. It’s from Google DeepMind, and they used it to train AI agents to play classic Atari 2600 games at the level of a human while only looking at the game pixels and the reward. In
danieltakeshi.github.io
An Analysis of Frame-skipping in Reinforcement Learning
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and comput
arxiv.org