-
[Paper Review] - IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner ArchitecturesReinforcement Learning 2022. 9. 2. 11:09
TL;DR
강화학습 에이전트를 더 빠르게 학습시키기위한 분산처리 아키텍처를 제안. 아키텍처는 비동기적으로 동작하는 Actor와 Learner로 구성되며, Off-policy 업데이트 방법인 V-trace를 제안하였음.
생각해봐야할 것
- 왜 분산 강화학습 알고리즘의 개발동기는 무엇일까?
- 알고리즘의 학습 루프에서 어떤 부분들이 병목현상을 일으키는가?
- IMPALA가 해결하고자 하는 것은 무엇인가? (contribution)
- Ape-X, A3C, Batched A2C, IMPALA 간의 차이점은 무엇일까?
- Retrace labmda 는 무엇인가?
Abstract
본 논문에서는 하나의 강화학습 에이전트에 단일 파라미터 셋을 사용해서 task 들의 large collection 을 풀고자 한다. 즉, 같은 환경을 여러 개를 시뮬레이션 해서 수집한 매우 많은 trajectory 들을 효율적으로 처리하는 것이 목적이다. 이를 위해 새로운 distributed agent인 IMPALA (Importance Weighted Actor-Learner Architecture)를 제안한다. 하나의 머신에서 리소스를 효율적으로 사용하고 수천 개 규모의 머신들에서 데이터 효율성 감소, 리소스 활용도 감소 없이 학습이 가능하다. (CPU와 GPU를 놀게 하지 않고 잘 사용한다는 것인데 어떻게 하는 것일까?) 에이전트의 acting과 learning을 분리하고 새로운 off-policy correction method인 V-trace를 사용해서 높은 throughput에서도 안정적인 학습을 가능하게 한다고 한다. 실험에서 DM-lab 30, Atari-57 환경에서 효율성을 입증했다. 그리고 multi task RL 에서 task 간의 positive transfer를 보였다고 한다.
Introduction
그동안 강화학습은 하나의 환경에서 에이전트가 좋은 퍼포먼스를 보이게끔 학습되어왔다. 각 테스크마다 분리되어 학습을 진행한 것이다. 본 논문에서는 다양한 테스크들의 집합을 동시에 학습시키고 평가하는 새로운 방법을 개발하는 것에 초점을 맞춘다. 기존의 SOTA 메소드인 A3C나 UNREAL 같은 경우 며칠에 걸쳐서 10억 개의 프레임들을 얻어야 하나의 도메인을 마스터할 수 있었다. 그런데 이 알고리즘들을 수십 개의 도메인에서 한 번에 학습시키는 것은 너무 느려서 비실용적이다.
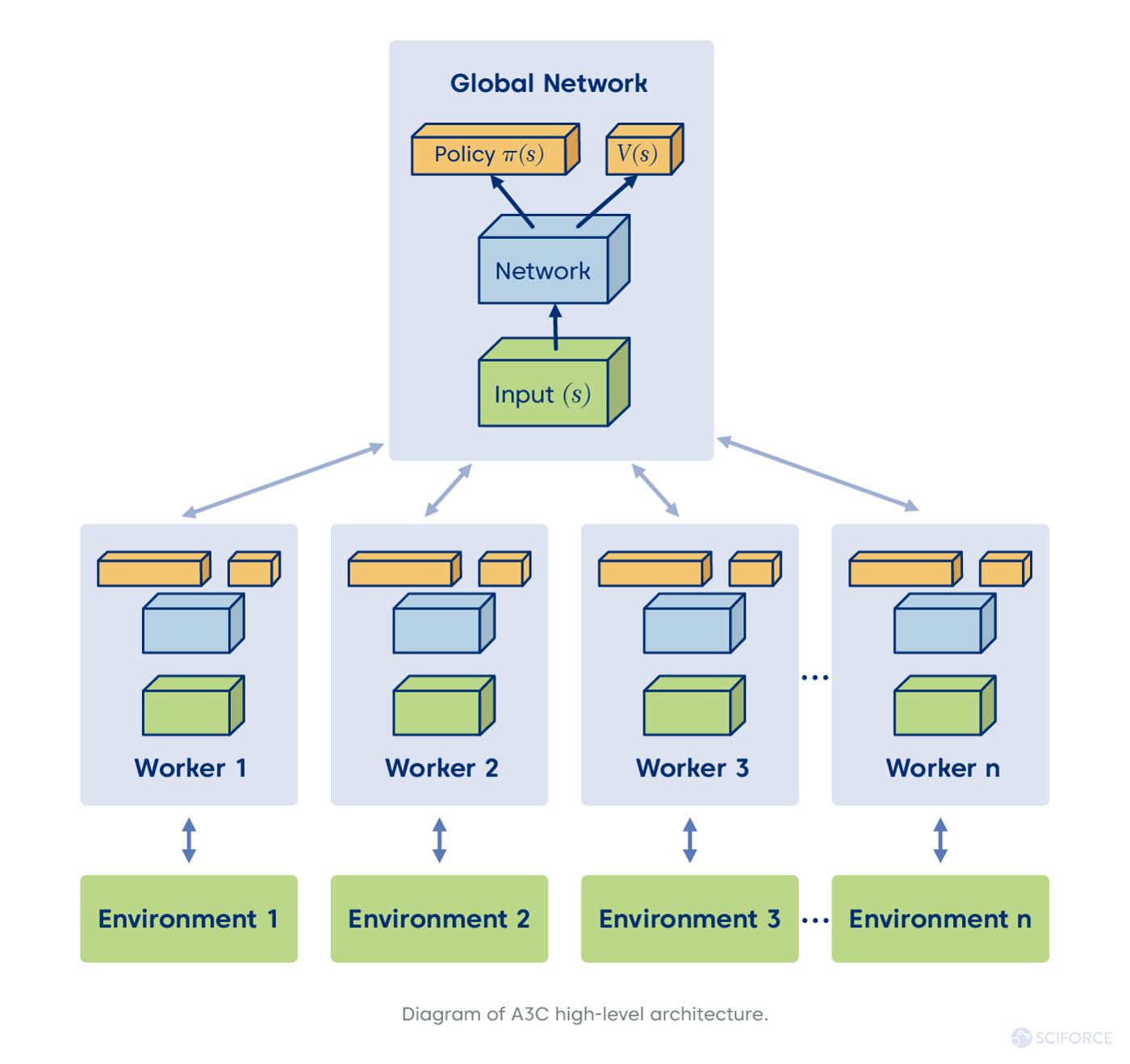
A3C의 경우 환경에서 rollout을 수행하는 Worker와 네트워크를 학습시키는 부분이 존재한다. 정책의 파라미터에 대한 그래디언트를 중심에 있는 파라미터와 커뮤니케이션하여 비동기적으로 업데이트한다. 반면 IMPALA의 Actor (worker)들은 경험의 trajectory들을 중앙의 러너와 커뮤니케이션한다. trajectory들의 미니배치에서 업데이트 하기 위해 GPU를 사용하고 시간에 독립적인 연산들은 모두 적극적으로 병렬화 한다. (이 부분이 해석이 좀 안되었는데, actor와 learner 사이에서 trajectory를 전송할 때 시간적 비용이 발생하므로 이 부분을 제외하고 모두 병렬화하는 것 같다)
이렇게 IMPALA를 활용하면 초당 25만 개의 프레임의 스루풋을 달성할 수 있다고 한다. (A3C 보다 30배나 빠르다!) 그리고 하이퍼파라미터와 네트워크 아키텍처에 더 강건하다고 한다.
Related Work

그림: rollout을 위한 다양한 아키텍처 A3C, Gorila, Ape-X, A2C 내용들이 나온다. 특히 batched A2C의 경우 여러 환경을 동시에 실행할 때, 가장 느린 환경이 전체 배치 단계의 수행 시간을 결정한다. 아타리 같은 환경에서는 렌더링 계산과정이 가벼워서 문제가 되지 않지만 물리 시뮬레이션 같은 복잡한 환경에서 돌릴 때, 에피소드의 길이가 다양한 상황일 때 문제가 된다고 한다. 그림에서 (a)의 경우 여러 개의 환경을 각 worker에 할당하여 병렬적으로 동작시켜서 batch state 를 만들어 낸 후, 이를 gpu 상의 master network에 입력으로 넣어 batch action을 출력한 다음 다시 각 worker에 돌려주는 식으로 동작한다. 그리고 n step 마다 업데이트를 진행한다. (b)의 경우는 정확하지는 않지만 master network 가 각 actor의 환경에서 n step 만큼 순차적으로 forward 연산을 진행하는 것으로 보인다. (a)는 배치단위로 해서 forward 연산을 4번 진행하고 (b) 배치단위로 연산하지 않아서 forward를 16번 진행한다. backward pass는 동일하게 진행한다. 이렇게 하면 특히 (b)의 경우 환경에서 rollout을 하는 동안 GPU를 잘 활용하지 못하게 된다.
IMPALA

Figure: IMPALA IMPALA의 경우 Actor Critic 구조를 사용하고, baseline으로 Value Function을 사용한다. 환경에서 경험을 생성하는 부분과 정책과 가치함수의 파라미터를 학습하는 부분을 분리하는 것이 핵심이다. (Actor와 Learner의 분리). 그림처럼 아키텍처는 여러 개의 액터들과 여러 개의 러너로 구성할 수 있다. 파라미터는 러너들 사이에서 분산되고 액터가 보내온 경험들을 사용해 타깃 정책 $\pi$를 학습한다. 액터는 러너들로부터 파라미터를 받아오고 observation들을 러너로 보내기만 한다. 데이터 효율성을 위해 파라미터 업데이트는 동기화된 방식을 사용한다.
학습과정은 다음과 같다.
- 처음으로 액터는 자기 자신의 local policy $\mu$를 가장 최근의 러너의 policy $\pi$로 업데이트한다.
- 환경에서 n번 스텝을 진행한다.
- n번 스텝을 진행하고, (1) 상태, 행동, 보상에 대한 trajectory, (2) initial LSTM hidden state, (3) local policy distribution $\mu$ 들을 queue를 통해서 learner로 전송한다.
- learner 는 queue 에 모인 많은 trajectory들을 큰 배치 텐서로 만들어서 학습한다.
- 위 과정을 반복한다.
이렇게 액터-러너 구조를 사용하면 커뮤니케이션 오버헤드가 낮아진다! 왜냐하면 A3C와 같은 알고리즘에서는 local policy로 gradient를 계산해서 전송했는데 이와는 달리 그저 경험만을 전송하면 되기 때문이다. 그러나 위 과정을 반복할 때 문제점이 발생한다. 액터가 rollout을 수행할 때 사용하는 정책과 러너가 학습할 때 사용하는 정책이 달라져서 둘의 policy-lag이 발생한다. 즉, 액터는 러너에 비해 뒤쳐진 정책을 사용할 수 밖에 없으며, Off-policy 업데이트를 수행하게 된다. 이를 해결하기 위해 V-trace 가 제안되었다.
Efficiency Optimisations
IMPALA에서 러너는 전체 trajectory 배치에 대해서 업데이트를 수행한다. 그래서 A3C 같은 온라인 에이전트보다 훨씬 더 많은 병렬화를 수행할 수 있다. (A3C에서는 local gradient 를 계산했었다) 러너는 모든 입력을 CNN으로 병렬처리해서 계산하는데, 시간축을 folding 해서 배치축으로 만든다. 그리고 output layer에 모든 time step들에 대해서 LSTM states가 병렬적으로 계산되도록 했다.
V-trace
정책 지연(policy-lag)으로 인해서 분산된 액터러너 구조는 off policy 학습을 수행하는 것이 중요하다. off policy는 환경에서 행동을 하는 정책 (behavior policy)와 학습 대상 정책 (target policy)가 다른 경우를 말한다. 이제 V-trace target을 살펴보자.
먼저, 행동 정책 $\mu$로부터 생성된 하나의 trajectory $(x_t, a_t, r_t)_{t=s} ^{t=s+n}$을 고려해보자. n-step V-trace target 을 다음과 같이 정의할 수 있다.
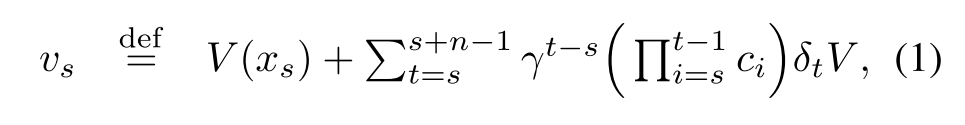
이때, $\delta_t V \overset{\rm def}= \rho _t (r_t + \gamma V(x_{t+1}) - V(x_t))$ 는 V에 대한 temporal difference이다. $\rho_t \overset{\rm def}= \min (\bar \rho, {\pi(a_t | x_t) \over \mu(a_t | x_t)})$, $c_i \overset{\rm def}= \min (\bar c, {\pi(a_t | x_t) \over \mu(a_t | x_t)})$ 는 truncated importance sampling weight를 의미한다.
$\bar c$가 1보다 크고, $c_i = 1, \rho_t = 1$이면 V-trace target은 on-policy의 n-steps 벨만 업데이트 식이 된다.

조금 더 살펴보자면, $c_i$는 Retrace알고리즘의 trace cutting과 비슷하며, $c_s \dots c_{t-1}$은 TD 값 $\delta_t V$가 특정 시간 s에서 가치함수의 업데이트에 얼마나 영향을 미치는지를 측정한다. $\pi$ 와 $\mu$가 더 다를 수록, weight들의 product 값은 더욱 커지게 된다. 분산을 줄이기 위해 $\bar c$라는 하한을 두었다.$\bar c$는 가치함수의 수렴속도에 영향을 주고 $\bar \rho$의 경우 가치함수의 수렴성질에 직접적인 영향을 미친다.
Experiments

Figure: Model Architecture 실험은 single task learning 상황과 multi-task learning 상황을 고려한다. 실험에 사용되는 아키텍처는 그림처럼 깊이가 얕은 모델, 깊은 모델 2 가지를 실험한다. 실험환경은 DM Lab 30, Atari 57에서 실험을 진행했다.
Computational Performance
IMPALA 의 설계 목적은 다음과 같다.

Table 1 - High throughput
- Computational Efficiency
- Scalability
다른 알고리즘보다 더 좋다는 것을 보이기 위해 A3C, Batched A2C와 비교실험을 수행했다. GPU를 사용하는 단일 머신 실험을 위해서 dynamic batching을 적용했다. (foward pass에서 배치 사이즈가 1이 되는 것을 막아준다) 표 1을 살펴보면 IMPALA가 두 테스크 모두에서 가장 좋은 성능을 보인다. 분산된 멀티 머신 실험에서는 scalability를 보여준다. 초당 25만 개의 프레임 throughput rate를 달성하고 하루에 210억 개의 프레임을 처리할 수 있다.
Single-Task Learning
1) Convergence and Stability
IMPALA 의 learning dynamics를 조사하기 위해서 5개의 DM Lab 환경에서 에이전트를 학습시켰다.

Figure 4 위 그림은 A3C, A2C와 비교 실험을 수행한 것이다. 대체적으로 좋은 성능을 보이는데, V-trace off policy correction이 더 좋은 성능을 내게 만든 것이라고 추측된다. 아래 행은 하이퍼파라미터 조합에 대한 성능 감소폭을 보인 것이다. 실험 결과, 하이퍼파라미터 값에 더 강건하다고 주장하고 있다.
2) V-trace Analysis

Figure: Average Final return V-trace의 구성요소들에 대한 ablation study를 진행했다. 총 4가지로 V-trace를 구성하고 있는 수식을 변형한 실험이다. 1) No corretion, 2) epsilon correction, 3) 1-step importance sampling, 4) V-trace 에 대해 실험했다.
3) Multi-Task Learning

이 실험에서는 모든 액터에서 같은 환경을 실행하는 것 대신, 고정된 숫자의 액터마다 다른 환경들을 할당했다. 예를 들어 48개의 액터가 있었다면 cartpole, pendulum, space invador, mountain car 등의 여러 환경들을 각각 할당하는 것이다. DMLAB-30 환경과 ATARI 57에서 실험을 진행했다. 아키텍처에 여러 가지 변형을 준 후, A3C와 비교한다. Mean capped human normalised score를 metric으로 사용했는데, 이는 하나의 테스크에서 사람을 능가하기보다는 여러 개의 테스크를 잘 푼다는 것을 강조하기 위함이다.
References
'Reinforcement Learning' 카테고리의 다른 글