-
[Paper Review] - Deep Reinforcement Learning at the Edge of the Statistical PrecipiceReinforcement Learning 2022. 9. 18. 20:47
논문을 읽은 이유
강화학습 논문을 구현하고 실험을 재현할 때, 논문대로 잘나오지 않는 것들이 너무나도 많았다. 하이퍼파라미터, 네트워크를 똑같이 설정했는데도 그대로 나오지 않았다. 이 때문에 performance metric에 문제가 있거나 실험횟수가 너무 적어서 그런 것이 아닌가 생각을 했어서 관련 논문을 찾다가 이 논문을 발견했다. 논문에서는 구간추정에 기반한 metric을 사용해야 한다고 주장한다. 논문을 제대로 이해하려면 통계적 추론에 대한 배경지식(신뢰구간, 가설검정)이 필요하다.
TL;DR
- 강화학습에서 에이전트의 성능을 비교하기 위해 사분위수 평균(interquartile mean score)을 사용할 것을 제안한다.
- 점추정치 (normalized median, mean score)로만 결론을 내는 것은 점수의 가변성을 다루지 못하므로 잘못된 결론에 이를 수 있다.
- 평가 프로토콜 (evaluation protocol)의 선택이 성능 개선을 보이는데 영향을 미칠 수 있다.
생각해볼 것들
- IQM은 어떻게 측정하는가?
-> 상위 25%, 하위 25% 의 실험 결과를 제거한 수치들을 사용한다. - Optimality gap이란 무엇인가?
Abstract
- 대부분의 Deep RL 연구에서는 벤치마크에서 성능을 비교할 때 task들 간의 평균이나 중앙값 같은 점추정치(point estimate)를 비교한다.
- 유한한 숫자의 학습을 시도할 때 내포되는 통계적인 불확실성을 무시한다. 계산을 많이 해야하는 벤치마크에서 연구가 전환되면서 task 당 실행횟수를 적게 평가하는 관행으로 인해 점추정만 하게 되면서 통계적 불확실성을 악화시킨 것이다.
- 본 논문에서는 조금만 환경을 실행하는 상황에서 평가 방식을 신뢰하려면 결과의 불확실성을 무시할 수 없다고 주장한다.
- 아타리 벤치마크에서 점추정을 통해서 얻은 결론과 철저히 통계적 분석을 한 결론 사이의 다름을 보인다.
- 저자들은 성능을 집계한 구간 추정 (interval estimates) 방식이 좋다고 한다.
- 결과의 가변성을 설명하고 더 강건하고 효율적은 metric 들을 표현하기 위해 performance profile 들을 제안한다. (interquartile mean scores). 필드에서 사용 가능한 오픈 소스 라이브러리 rliable 도 제안한다.
1. Introduction
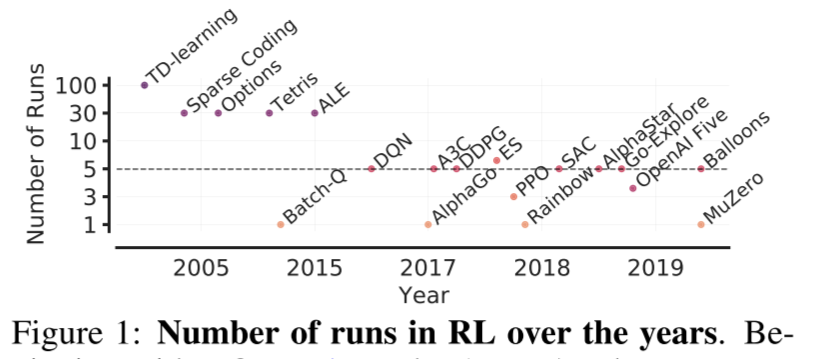
- 강화학습의 성능 지표로 평균과 중앙값 같은 주로 point estimate 값을 사용한다.
- 학습 실행을 적게 하는 것은 강화학습 알고리즘의 퍼포먼스에 상당한 가변성과 관련 있다.
- 그림처럼 연구에서는 대부분 3번에서 10번 학습을 실행한다.
- 더 많이 실행하면 불확실성을 줄일 수 있지만 계산비용 때문에 제한이 있다. 예를 들어, standard protocol을 이용해서 50개가 넘는 아타리 2600 게임들을 5번을 실행하려면 1000개의 GPU로 며칠을 학습시켜야 한다.
- 통계적인 불확실성을 무시하는 것은 연구의 결론을 잘못된 방향으로 이끌 수 있다. 그리고 정확히 같은 무작위 조건에서도 연구의 내용을 재현하기 어렵게 만든다. 평균값의 경우 이상치에 영향을 받고 중앙값의 경우 0인 점수에 따라 많이 변하기 때문에 사분위수 평균(interquartile mean)을 사용할 것을 주장한다.
2. Formalism
- $M$ 개의 task들을 평가하는 강화학습 환경을 고려해보자. 각 task에 대해서 $N$ 번의 독립적인 실험을 수행한다.
- 이를 통해 normalized score를 얻을 수 있다. 표기는 $x_{m,n}$으로 하며, $m= 1, \dots, M, \quad n= 1, \dots, N$ 이다. 이 스코어는 각 테스크마다 랜덤 policy의 경우 0점, 사람의 점수를 1점을 주는 방식으로 정규화해서 계산한다. normalized score set을 $x_{1:M, 1:N}$으로 표기한다.
- 대부분의 실험에서 다른 실험들을 통해 얻은 점수에는 랜덤성이 내포되어 있다. 이는 1) 테스크의 stochasticity, 2) 학습 과정에서의 만들어진 탐험적 선택, 3) 랜덤으로 초기화된 파라미터, 4) 소프트웨어나 하드웨어의 non-determinism 들이 원인이다.
- 그래서 저자들은 알고리즘의 m번째 작업에서 정규화된 점수를 랜덤변수 $X_m$으로 모델링한다. 그러면 점수 $x_{m,n}$은 랜덤변수 랜덤변수 $X_m$의 분포에서 뽑아진 $X_{m,n}$의 관측값(realization)이 된다.
- 어떤 실수 $\tau \in \mathbb R$에 대해서 $X_m$의 tail distribution $F_m(\tau) = P(X_m > \tau)$ 로 정의한다.
- 수집된 어떤 점수들을 $y_{1:K}$라고 하면, empricial tail distribution function은 다음처럼 주어진다. $\hat F(\tau; y_{1:K}) = {1\over K} \sum_{k=1}^K 𝟙 [y_k > \tau].$
- 특히 $\hat F_m (\tau) = \hat F(\tau ; x_{m, 1:N}) $으로 표기한다.
- 알고리즘의 Aggregate performance 는 normalized scores의 집합 $x_{1:M, 1:N}$을 스칼라 값으로 mapping한다.
- 두 개의 prevalent aggregate performance metric은 평균과 중앙값이다. 만약 특정 task $m$을 $N$번 실행한 평균 점수를 $\bar x_m = {1\over M} \sum_{n=1}^N x_{m,n}$ 라고 표기한다면, 전체 task에대한 평균과 중앙값은 $\text {Mean} (\bar x_{1:M})$과 $\text {Median} (\bar x_{1:M})$이 된다. 정확하게는 우리는 이를 task 평균에 대한 표본 평균과 표본 중앙값이라고 부른다. (sample mean, sample median으로 부르는 이유는 각 테스크를 N번 실행해서 계산했기 때문)
- $\bar x_m$은 랜덤변수 $\bar X_m = {1\over N} \sum_{n=1}^N X_{m,n}$의 관측값이기에 표본평균과 중앙값들은 랜덤변수 ${Mean} (\bar X_{1:M})$과 $\text {Median} (\bar X_{1:M})$의 점추정치들이다. 실험을 무한히 진행하면 평균과 중앙값에 대한 참값을 얻을 수 있다.
Confidence intervals
- 신뢰구간 (Confidence intervals)은 true score에 대한 plausible value들의 추정치로써 해석될 수 있다.
- $\alpha \times 100%$ CI는 어떤 구간을 계산하는데, 만약 실험을 다시 수행하고 다른 실험 집합을 사용해서 신뢰구간을 구성하는 경우, 실제 점수를 포함하는 계산된 신뢰구간의 비율이 $\alpha \times 100%$가 되도록 구간을 계산한다. 여기서 $\alpha \times [0,1]$은 norminal converage rate이다. 95%의 신뢰구간이 일반적으로 사용된다.
- 만약 true score가 95%의 신뢰구간 밖에 있다면 sampling event는 5%의 확률로 우연히 발생한 것이다.
Remark
- 저자들은 결과의 불확실성을 측정하기 위해 신뢰구간을 사용할 것은 추천한다. 그리고 주어진 데이터에 대해서 effect sizes (베이스라인에 대한 성능향상)을 보이라고 한다.
- 또한 통계적 사고를 할 것을 강조하지만, 통계적 검정(p-value < 0.05) 같은 것은 피하라고 한다.
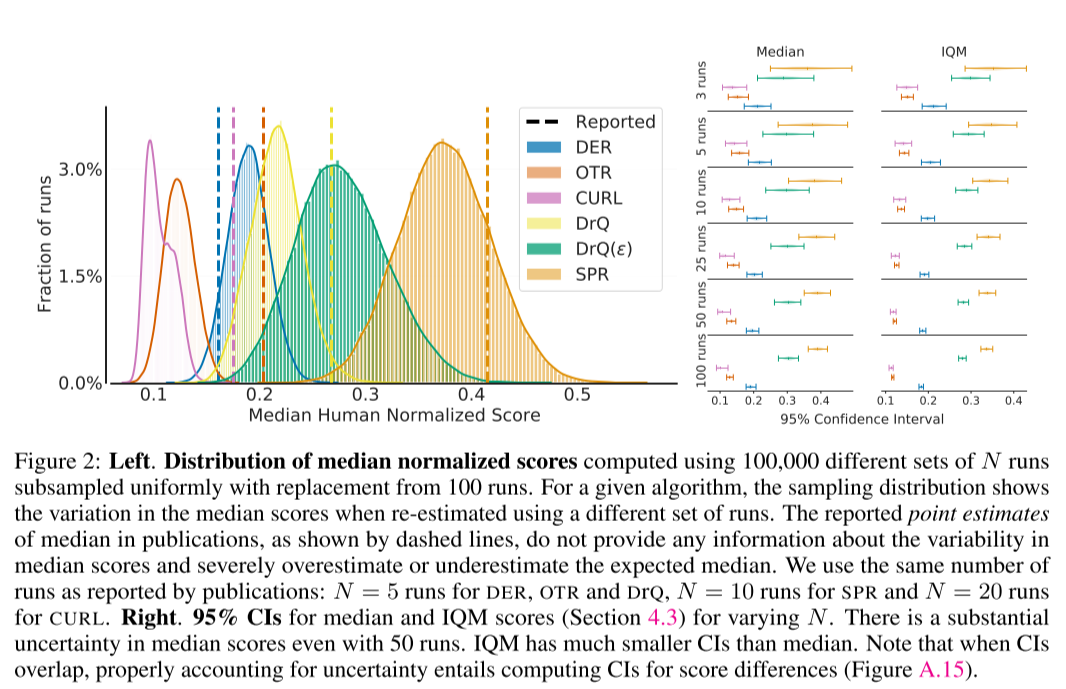
그림 2를 살펴보자. median normalized score에 대한 확률분포를 그린 것이다. 100 번의 실험수행에서 균일하게 부분 표본추출하여 N번 실행의 10만 개의 다른 실험집합을 만들어서 계산했다. 즉 100개의 실험결과가 있으면, 5개씩 표본추출해서 이에 대한 표본중앙값들을 10000개를 만들어서 분포를 만들어낸 것이다. 표본추출된 분포는 다른 실험결과의 집합을 사용했을 때, 중앙값의 variation을 보여준다. 그동안 발표된 논문들에서 중앙값에 대해 보고된 점추정치들은 중앙값이 얼마나 변할 수 있는지 제공해주지 않는다. 그리고 평균 중앙값에 대해 과다하게 추정되거나 과소하게 추정되었을 수 있다. (overestimate, underestimate). 논문들에서 사용된 것처럼 $N=5$로 DER, OTR, DRQ에 대해 분포를 만들었고, $N=10$으로 SPR을 계산, $N=20$으로 CURL을 계산했다.
오른쪽 그림은 중앙값에 대한 95%의 신뢰구간과 다양한 N에 대한 IQM의 점수들이다. 50번의 수행에서도 중앙값이 상당한 불확실성을 가진다!!! IQM은 중앙값보다 더 작은 신뢰구간을 가지고 있다. 신뢰구간이 중복될 때 불확실성을 적절히 설명하려면, 점수차이에 대한 신뢰구간을 계산해야 한다.
3. Case Study: The Atari 100k benchmark
- 실험을 적게 실행할 때, 단순히 점추정치를 사용하는 상황에서 발생할 수 있는 함정에 대해 케이스 스터디를 통해 설명한다. 케이스 스터디는 Atari 100k 벤치마크를 다루는데 이는 데이터 효율성을 평가하기 위한 ALE의 offshoot이다.
- 이 벤치마크에서는 알고리즘들이 26개의 게임에 대해서 100k 스텝들 (2~3 시간)에 대해서 평가된다. 이전의 논문에서 보고된 결과들은 3~5 번의 실험수행을 해서 결과를 냈었다. 드물게 10번, 20번 하는 경우도 있었다.
- 케이스 스터디는 최근 다섯 개의 deep RL 알고리즘에 대해 비교 한다. DER, OTR, DRQ, CURL, SPR를 선택했는데 이 벤치마크에서 representative, influential 한 알고리즘들이기 때문이다.
- 하나의 게임에 대한 좋은 성능은 다른 게임에서의 성능에 대한 정보를 제공하지 않고도 높은 표본평균을 제공할 수 있기에, 전체 테스크에 대한 표본중앙값을 사용하여 성능을 측정하는 것이 일반적이다.
- 각 알고리즘에 대해 100개의 독립적인 실험(100 independent run)을 수행하고 평가해서 few-run regime에서의 statistical variation들을 조사한다. 하나의 실험에 대한 점수는 100개의 evaluation episoodes에 대한 average return이다.
- 각각의 실험수행은 하나의 알고리즘을 벤치마크에 있는 26개의 알고리즘에 대해 학습시키는 것에 해당한다. (1 run = 1 algorithm training for 26 games)
- 즉, 하나의 알고리즘 당 $26 \times 100$ 개의 점수들을 얻는다. 여기서 저자들은 3-100번의 실험들을 부분적으로 표본추출한다.
- subsampled score들은 점추정치의 집합을 생성하는데 사용된다. 이를 통해 statistical variability를 측정할 수 있다.
High variability in reported results
- 실험에서 처음으로 관측된 것은 sample medians들이 상당한 변동성을 보인다는 것이다. (적은 수의 sample runs에 의존하는 무작위한 양들로 볼 때 확률분포가 상당히 넓다는 뜻인 것 같다)
- 이것은 점추정치만 사용했을 때, 오류가 있는 결론으로 이어질 수 있는 가능성이 상당하다는 것을 보인다! (논문에서 제안하는 알고리즘이 성능이 좋다는게 오류가 있을 수 있는 것이다)
- 즉, 몇 번의 실험을 수행할 때 점추정치는 "다른 실험 집합으로 알고리즘을 재평가하더라도 동일한 결론을 이끌어내는가?"에 대한 답을 제공하지 못한다는 것이다.

Substantial bias in sample medians
- 샘플 중앙값은 참인 중앙값에 대하여 편향된 추정량이다. (biased estimator of true median)
- 즉, 일반적으로 $\mathbb E[\text {Median}(\bar X_{1:M})] \neq \text {Median} \mathbb E[X_{1:M}])$이다.
- few-run의 regime에서 bias가 알고리즘 간의 비교를 dominate할 수 있음을 그림 3에서 볼 수 있다. (실험횟수 N에 따라 알고리즘 간의 비교 결과가 달라질 수 있다)
Statistical concerns cannot be satisfactorily addressed with few runs.

- 3번 혹은 적은 횟수의 실험으로 성능이 개선되었다고 주장하는 것은 믿기 어려울 수 있다.
- 실험적으로 강화학습에서의 folk wisdom에 따르면 20번 혹은 30번의 실험수행이면 충분하다고 한다.
- 다양한 실행 횟수 (그림2 오른쪽)에 대한 샘플 중앙값에 대한 신뢰구간을 계산하면 이 수치가 아타리에서 50~100회의 실험 수행에 더 가까운 것을 볼 수 있다. 그러나 이는 대부분의 연구 프로젝트에서 실행하기에 너무 계산량이 많다.
- 하나의 알고리즘이 더 낫다고 알려진 상황을 고려보자. 실행횟수를 다양하게 할 때, 성능 차이를 정확하게 평가하려면 Median과 IQM에 대한 신뢰도는 몇이 되어야할까?
- 구체적으로 저자들은 SPR을 포함하는 동일한 두 개의 N번의 실험을 고려한다. 이때, 실험 점수 중 하나를 고정된 비율로 인위적으로 부풀리눈 것을 제외한다.
- In particular, l = 0 corresponds to running the same experiment twice but with different runs. We find that statistically defensible improvements with median scores is only achieved for 25 runs (l = 25) and 100 runs
(l = 10). With l = 0, even 100 runs are insufficient, with deviations of 20% possible.
Changes in evaluation protocols invalidates comparisons to prior work.

- 강화학습 알고리즘의 퍼포먼스를 측정하기 위해 전형적이고 비교적 안전한 접근은 마지막 트레이닝 에피소드들에서 받은 점수를 평균하는 것이다. 그러나, 이 field에서는 여러 개의 대안적인 프로토콜이 사용된 것을 볼 수 있다.
- 예를 들어, 여러 번의 실험 또는 학습 과정에서 달성된 최대평가점수를 사용하는 것이 있다. 비슷한 프로토콜이 CURL과 SUNRISE에서 사용되었다.
- 최댓값을 포함하는 대안적인 프로토콜에서 생성된 결과는 일반적으로 최종적인 성능으로 보고된 결과와 비교할 수 없다. Atari 100k에서 두 프로토콜이 실제 점수 차이보다 훨씬 더 큰 결과를 만들어내는 것을 그림 5에서 보이고 있다.
- 특히 CURL의 프로토콜로 DER을 평가하면 CURL에 대해서 보고된 점수보다 훨씬 높은 점수가 나온다.
- 즉, 평가 절차의 갭으로 인해, CURL이 DER보다 더 큰 true median score를 달성하는 것으로 평가되었다.
- 저자들의 실험으로 DER이 CURL보다 더 좋다는 어떤 근거를 제공한다. 마찬가지로 DER에 비해 SUCRISE의 수많은 개선이 평가 프로토콜의 변경으로 설명될 수 있음을 발견했다.
4. Recommendations and Tools for Reliable Evaluation
- 위의 케이스 스터디즌 통계적 불확실성 이슈를 해결하기 위해 필요한 실험횟수의 증가가 계산량이 너무 많아서 실행 불가능함을 보인다. 이 섹션에서는 few-run regime에서도 실험결과보고의 질을 향상시키기 위한 세 가지 툴을 확인한다.
4.1 Stratified Bootstrap Confidence Intervals
- 알고리즘의 aggregate performance가 존재할 것으로 추정되는 범위를 나타내기 위해 구간 추정을 보고하는 것의 중요성을 재차 확인해본다.
- 구체적으로는 stratified sampling으로 bootstrap CIs를 사용하는 것을 제안한다. 이 방법은 적은 샘플 사이즈에 적용될 수 있고, 샘플표준편차를 보고하는 것보다 더 정당화될 수 있다.
- 이전의 논문들에서는 N번 실행된 단일 task average score의 uncertainty를 보고하기 위해 bootstrap CI를 사용할 것을 권장했었지만, 이는 N이 작을 때는 유용하지 않다. 왜냐하면 bootstrapping이 데이터로부터 re-sampling 하는 것이 true distribution으로부터 샘플링하는 것을 근사한다고 가정하기 때문이다.
- 총 MxN 개의 랜덤한 샘플들을 전반적인 task에 걸쳐 집계하면 더 나은 것을 할 수 있다.
- To compute the stratified bootstrap CIs, we re-ample runs with replacement independently for each task to construct an empirical bootstrap sample with N runs each for M tasks from which we calculate a statistic and repeat this process many times to approximate the sampling distribution of the statistic.
- We measure the reliability of this technique in Atari 100k for variable N, by comparing the nominal coverage of 95% to the “true” coverage from the estimated CIs (Figure 6) for different bootstrap methods (see [30] and Appendix A.5). We find that percentile CIs provide good interval
estimates for as few as N = 10 runs for both median and IQM scores (Section 4.3).
4.2 Performance Profiles
대부분의 강화학습 벤치마크에서는 테스크들 마다 다른 스코어를 산출한다. 그리고 스코어는 heavy-tailed, multimodal 일 수도 있고 이상치 값들을 가질 수도 있다. 평균이나 중앙값 값들을 사용하는 것 대신에 performance profile 들을 사용할 것을 추천한다.
- run-score distributions 또는 score distribution이라 불리는 performance profile 제안한다. 특히 few-run regime에서 적합하다고 한다.
- Score distribution 특정 정규화된 점수 상에서의 실행의 비율을 보여준다. 식은 다음과 같이 주어진다.

- 이 점수 분포를 사용하는 것의 장점은 underlying distribution $F(\tau) = {1\over N} \sum_{m=1}^M F_m(\tau)$ 에 대한 불편추정량이라는 것이다.
- 다른 장점으로는 극단적으로 높은 점수를 가진 outlier run이 어떤 $\tau$ 값에 대해서도 점수분포의 결과가 변할 수 있다는 것이다. (최댓값은 1)
4.3 Robust and Efficient Aggregate Metrics
1) IQM, Optimality gap, Probability of improvement
- median을 사용하는 대신에 사분위수 평균을 추천한다. 실험결과에서 하위 25%, 상위 25%를 제거하고 50%의 실험 결과만 사용하는 것이다.
- mean 대신에 optimality gap을 사용할 것은 추천한다. 이는 어떠한 양인데, 알고리즘이 최소 점수 $\gamma= 1.0$을 충족시키지 못하는 횟수이다. 예를 들어, 사람 수준의 성능을 얻는 것이 목표라고 하면, 1.0의 정규화된 점수는 그다지 중요하지 않은 목표라고 가정한다. 문제마다 threshold는 다르게 선택될 수 있다.
- 한 알고리즘 $X$가 $Y$보다 얼마나 강건하게 개선되는지에 관심 있다면 average probability of improvement를 고려하는 것이 좋다. 이 메트릭은 랜덤으로 선택된 테스크에 대해서 알고리즘 X가 알고리즘 Y보다 얼마나 더 좋은 성능을 내는지를 보여준다. 특히, $P(X > Y) = {1\over M}\sum_{m=1}^M P(X_m > Y_m)$ 값은 task m에 대해서 Y보다 X가 나을 확률이다. 주의할 것은 IQM 이나 optimality gap과는 달리 이 메트릭은 개선의 크기를 설명하지 않는다는 것이다.
5. Re-evaluating Evaluation on Deep RL Benchmarks
아타리 벤치마크에서 200M 개의 프레임에 대해 에이전트를 학습시킨 것은 가장 널리 알려진 벤치마크다. 몇 개의 인기 있는 메소드들을 결과의 uncertainty를 무시한 것과 고려한 것의 차이를 실험적으로 보인다.
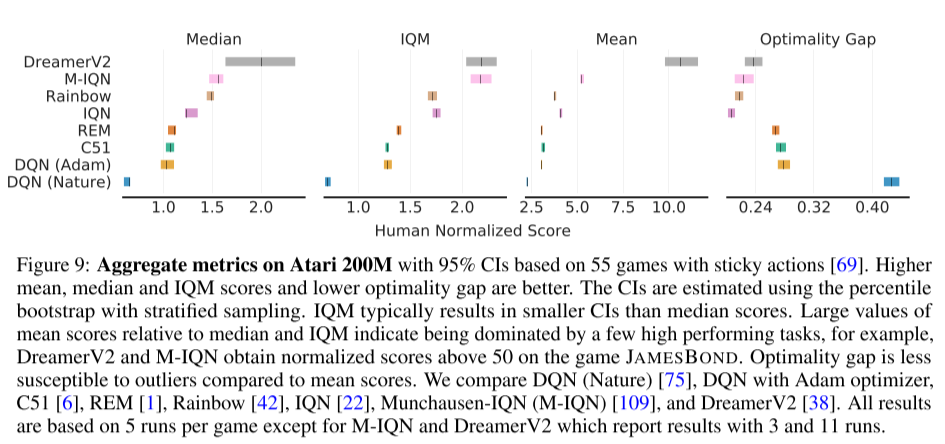
- Dreamer V2의 경우 집계된 점수에 상당한 불확실성을 보인다.
- M-IQN은 Rainbow보다 더 좋은 성능을 보인다.
- C51은 DQN보다 상당히 좋다고 여겨지지만 둘의 구간 추정치는 꽤나 겹쳐져 있다.
- 그림 9는 aggregate metric들에 대한 한계점들을 보여준다. metric의 선택에 따라 알고리즘의 순서가 변화할 수 있는 것이다. 순위를 매기는 것의 비일관성은 이러한 metric들이 task와 실험 수행들에서 전체 성능의 특정한 면만 포착한다고 볼 수 있다.

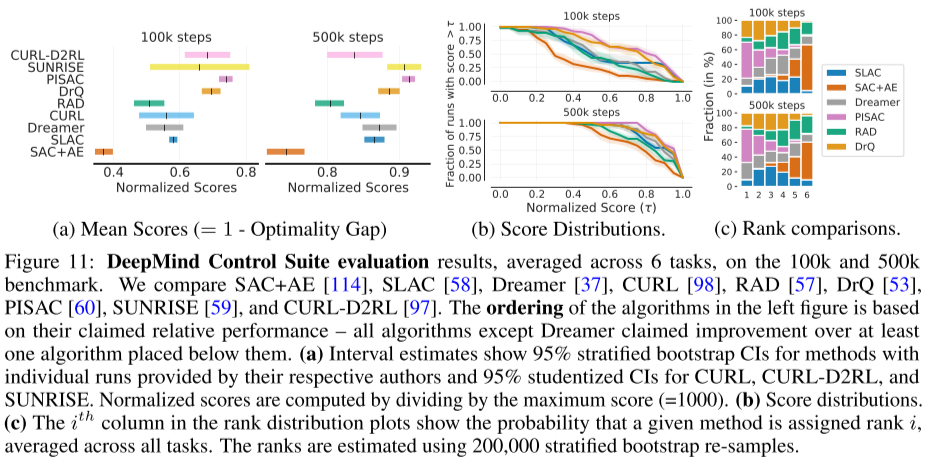

- 아타리와 여러 벤치마크 환경에서의 case study를 통해서 통계적인 이슈들이 보고된 결과들에 상당한 영향을 끼칠 수 있다는 것을 볼 수 있다.
References
[1] Deep Reinforcement Learning at the Edge of the Statistical Precipice, https://arxiv.org/abs/2108.13264
[2] https://github.com/google-research/rliable
[3] https://www.youtube.com/watch?v=XSY9JwqD-bw&t=4s&ab_channel=RishabhAgarwal
'Reinforcement Learning' 카테고리의 다른 글