-
RNN Policy 에 관하여 - (1)Reinforcement Learning 2022. 10. 14. 16:28
강화학습을 여러 문제에 적용하면서 보통은 Policy의 아키텍처를 FC layer나 CNN으로 설정한다.
Partially Observable한 문제를 해결하기 위해 state를 쌓아서 policy input으로 많이 사용하는데 RNN을 사용해서 해결할 수도 있다. Policy에 단지 RNN을 추가했을 뿐인데 전체적인 학습 과정에서 꽤나 변화가 발생한다. 이번 포스팅에서는 RNN Policy의 전반적인 내용을 정리한다.
1. RNN

그림 1: RNNCell 보통 시퀀스를 처리하는 RNN의 구조는 위 그림과 같다. 원에 해당하는 것은 변수들이고 사각형은 뉴럴네트워크다. RNN은 이전시점의 은닉상태 $h_{t-1}$와 현재 시점의 입력 $x_{t}$을 받아서 $h_{t}$를 출력한다. RNN이 LSTM 인지, GRU 인지에 따라 $h_{t}$읙 구성이 바뀌게 된다. LSTM이면 output, (hidden state, cell state)를 리턴하고, Vanila RNN, GRU면 output, hidden state만을 리턴한다.
$output$의 경우 $(L, N, H_{out})$의 텐서가 출력되며, $h_t$의 경우 $(num\_ layers, N, H_{out})$ 형태의 텐서가 출력된다. 여기서 중요한 것은 RNNCell과 RNN의 차이이다. RNN은 RNNCell을 일반화한 것이다. 여러 개의 RNN Cell을 쌓아서 RNN을 만들 수 있다.
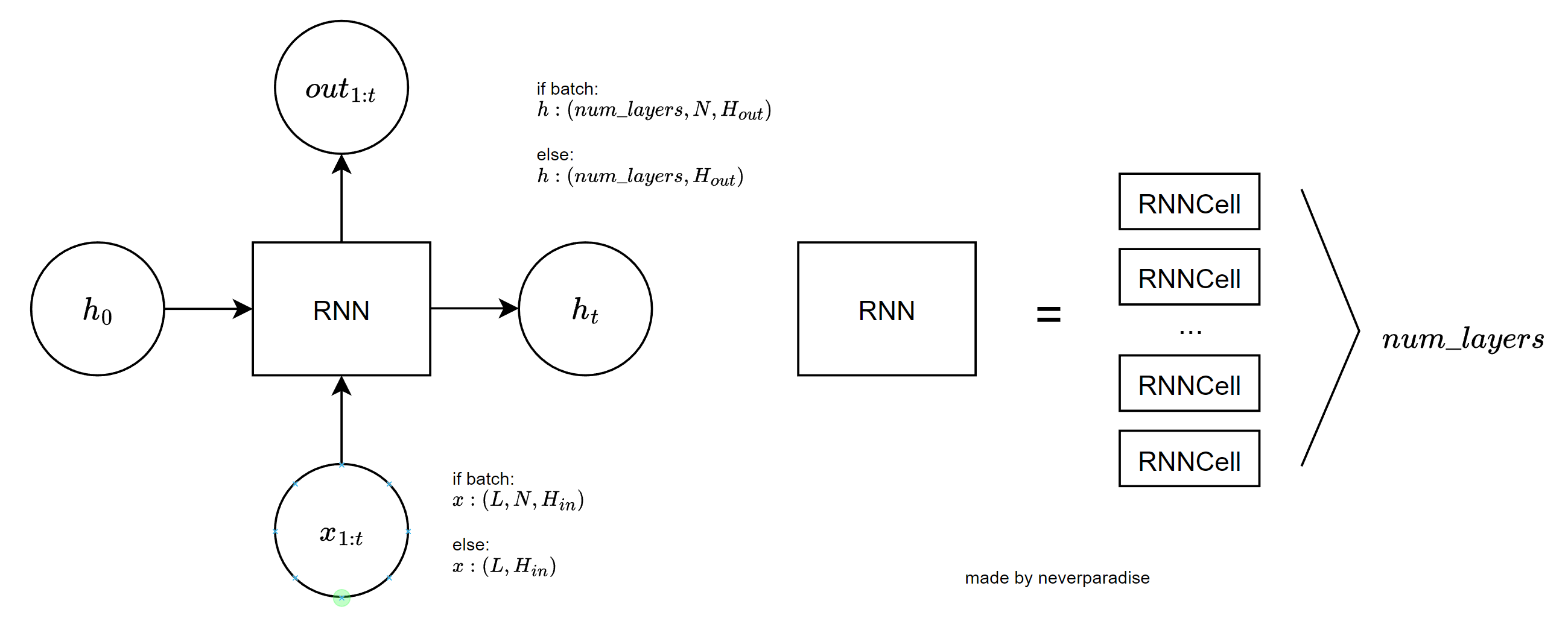
그림 2: RNN 
그림 3: RNN Detail RNN은 $(L, H_{in})$ 또는 $(L, N, H_{in})$ 형태의 텐서를 입력받는데 *시퀀스를 한 번에 입력받는다.* 만약 batched tensor를 처리하고 싶다면 각 모든 시퀀스들을 길이 $L$로 맞춰줘야 한다. RNNCell의 경우 시퀀스 텐서의 한 timestep 값인 $(N, H_{in})$ 텐서를 입력받는다.
의문을 가져볼만 한 것은, output의 경우 hidden state의 값을 순차적으로 시간에 따라 수집한 값들이다. hidden의 경우 마지막 스텝이 끝나고의 hidden state 값인데, 이미 output[-1]을 통해 hidden에 접근할 수 있는데 왜 굳이 리턴을 두 개로 만들었을까?
2. RNN Value, Policy

그림 4: RNN Value, Policy 이제 RNN으로 Value와 Policy를 매개변수화하는 상황을 생각해보자. 환경을 초기화 한다음, 값이 0으로 채워진 init_hidden_state를 만들고 policy에 넣어주면서 rollout을 하면 될 것 같다. 아래 그림에서는 hidden이 드러나게 pesudo code를 작성했지만, 실제 구현할 때는 hidden을 멤버변수로 선언해서 rollout 과정에서 드러나지 않게 할 것이다.

Figure: pseudo code 여기서 문제가 되는 것은 우리는 그림 2처럼 RNNCell이 아닌 RNN을 사용할 것이라는 점이다. 위에서 설명한대로 RNN은 $(L, N, H_{in})$ 형태의 텐서를 입력받는다. 즉, 텐서에 시퀀스 차원이 포함되어야 한다!! 이 때문에 RNNPolicy Class 에서 forward 함수를 만들 때 여러 가지 경우를 고려해야 한다.
우선, training 중과 training이 아닐 때를 구분한다.
- training 중에는 (L, N, state_dim)의 텐서가 네트워크의 입력으로 들어온다.
- evaluation 중에는 (state_dim) 하나의 텐서가 입력으로 들어온다. (state가 이미지일 수도 있어서 텐서라고 표현했다)
핵심은 if else 문을 활용해서 input의 shape에 따라 경우를 나누어서 처리하는 것이다.
- 입력이 state 하나만 들어오는 경우 unsqueeze()나 reshape()를 활용해서 (1, 1, state_dim)의 텐서로 만들어준다.
- 입력이 배치 단위의 시퀀스인 경우 그대로 네트워크를 통과시킨다.
1) LSTM이 전체 네트워크에서 제일 앞단에 위치한 경우
if else 문을 활용해서 input의 shape에 따라 경우를 나누어서 처리한다.
- 입력이 state 하나만 들어오는 경우 unsqueeze()나 reshape()를 활용해서 (1, 1, state_dim)의 텐서로 만들어준다.
- 입력이 배치 단위의 시퀀스인 경우 그대로 네트워크를 통과시킨다.
2) 네트워크 앞단에 FC Layer나 Conv Layer가 있어서 중간에 LSTM이 위치한 경우
FC Layer나 통과 시킨 Conv Layer를 통과시킨 값들을 RNN의 input shape에 맞게 reshape해야 한다.
training 중에는 어떤 Linear layer의 입력으로 (L, N, state_dim)가 들어올 것이다. training 중과 evaluation 중인 경우를 나누어서 처리해야 한다.
Code
# rnn_policy.py
import torch import torch.nn as nn import torch.nn.functional as F from torch.distributions import Categorical, Normal from torch.utils.data.sampler import BatchSampler, SubsetRandomSampler def get_init_lstm_state(num_rnn_layers, hidden_dim, batch_size, is_training, device): if is_training: hidden = torch.zeros(num_rnn_layers, batch_size, hidden_dim).to(device) else: hidden = torch.zeros(num_rnn_layers, 1, hidden_dim).to(device) return hidden class RNNPolicy(nn.Module): def __init__(self, args) -> None: super().__init__() # information self.is_continuous = args.is_continuous self.state_dim = args.state_dim self.linear_dim = args.linear_dim self.hidden_dim = args.hidden_dim self.action_dim = args.action_dim self.batch_size = args.batch_size self.device = torch.device(args.device) self.num_rnn_layers = args.num_rnn_layers # network self.fc = nn.Linear(args.state_dim, args.linear_dim) self.gru = nn.GRU(args.linear_dim, args.hidden_dim, \ num_layers=self.num_rnn_layers, bias=True) if self.is_continuous: self.mean = nn.Linear(self.hidden_dim, self.action_dim) self.std = nn.Linear(self.hidden_dim, self.action_dim) else: self.policy_logits = nn.Linear(args.hidden_dim, self.action_dim) def _format(self, state, device): x = state if not isinstance(x, torch.Tensor): x = torch.tensor(x, dtype=torch.float32) x = x.to(device=device) else: x = x.to(device=device) return x def forward(self, state): state = self._format(state, self.device) if len(state.shape) < 3: state = state.reshape(1, 1, -1) self.hidden = get_init_lstm_state(self.num_rnn_layers, self.hidden_dim, \ batch_size=1, device=self.device, is_training=False) x = F.leaky_relu(self.fc(state)) x, self.hidden = self.gru(x, self.hidden) x, self.hidden = torch.tanh(x), torch.tanh(self.hidden) if self.is_continuous: mu = torch.tanh(self.mean(x)) std = F.softplus(self.std(x)) dist = Normal(mu, std) else: logits = self.policy_logits(x) prob = F.softmax(logits, dim=-1) dist = Categorical(prob) return dist def choose_action(self, state, is_training=False): dist = self.forward(state) action = dist.sample() if is_training: return action, dist.log_prob(action) else: while len(action.shape) != 1: action = action.squeeze(0) return action.detach().to('cpu').numpy(), dist.log_prob(action).detach().to('cpu').numpy()3. Policy execution
이제 코드를 실행시켜보자 환경 코드는 다음과 같다.
# point_env.py
"""Simple 2D environment containing a point and a goal location.""" import math import numpy as np import random import seaborn as sns import matplotlib.pyplot as plt from gym import Env from gym import spaces, spec import torch import pygame, sys from pygame.locals import * import time def semi_circle_goal_sampler(): r = 1.0 angle = random.uniform(0, np.pi) goal = r * np.array((np.cos(angle), np.sin(angle))) return goal def circle_goal_sampler(): r = 1.0 angle = random.uniform(0, 2*np.pi) goal = r * np.array((np.cos(angle), np.sin(angle))) return goal GOAL_SAMPLERS = { 'semi-circle': semi_circle_goal_sampler, 'circle': circle_goal_sampler, } from gym import Env from gym import spaces device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def semi_circle_goal_sampler(): r = 1.0 angle = random.uniform(0, np.pi) goal = r * np.array((np.cos(angle), np.sin(angle))) return goal def circle_goal_sampler(): r = 1.0 angle = random.uniform(0, 2*np.pi) goal = r * np.array((np.cos(angle), np.sin(angle))) return goal GOAL_SAMPLERS = { 'semi-circle': semi_circle_goal_sampler, 'circle': circle_goal_sampler, } class PointEnv(Env): """ point robot on a 2-D plane with position control tasks (aka goals) are positions on the plane - tasks sampled from unit square - reward is L2 distance """ def __init__(self, max_episode_steps=100, goal_sampler=None, is_render=False): self.is_render = is_render if callable(goal_sampler): self.goal_sampler = goal_sampler elif isinstance(goal_sampler, str): self.goal_sampler = GOAL_SAMPLERS[goal_sampler] elif goal_sampler is None: self.goal_sampler = semi_circle_goal_sampler else: raise NotImplementedError(goal_sampler) self.reset_task() self.task_dim = 2 self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(2,)) # we convert the actions from [-1, 1] to [-0.1, 0.1] in the step() function self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(2,)) self._max_episode_steps = max_episode_steps if self.is_render == True: pygame.init() self.fpsClock = pygame.time.Clock() self.width = 600 self.height = 600 self.window = pygame.display.set_mode((self.width,self.height), 0, 32) pygame.display.set_caption('PointEnv') def sample_task(self): goal = self.goal_sampler() return goal def set_task(self, task): self._goal = task def get_task(self): return self._goal def reset_task(self, task=None): if task is None: task = self.sample_task() self.set_task(task) return task def reset_model(self): self._state = np.zeros(2) return self._get_obs() def scale(self, array): new_x = 2 * (array[0] - self.width / 2) / self.width new_y = 2 * (array[1] - self.height / 2) / self.height new_array = np.array([new_x, new_y]) return new_array def upscale(self, array): new_x = array[0] * self.width / 2 + self.width / 2 new_y = array[1] * self.height / 2 + self.height / 2 new_array = np.array([new_x, new_y]) return new_array def render(self, mode, tick): if mode=='text': print(f'State: {self._state}, Goal: {self._goal}') elif mode=='rgb': time.sleep(tick) #background_color=(255, 255, 255) #self.window.fill(background_color) 없으면 경로 남음 goal_state = self.upscale(self._goal) agent_state = self.upscale(self._state) pygame.draw.circle(self.window, (0, 255, 0), goal_state, 4) pygame.draw.circle(self.window, (255, 0, 0) , agent_state, 4) pygame.display.update() def reset(self): obs = self.reset_model() if self.is_render==True: background_color=(255, 255, 255) self.window.fill(background_color) pygame.display.update() goal_state = self.upscale(self._goal) agent_state = self.upscale(obs) pygame.draw.circle(self.window, (0, 255, 0), goal_state, 4) pygame.draw.circle(self.window, (255, 0, 0) , agent_state, 4) pygame.display.update() return obs def _get_obs(self): return np.copy(self._state) def step(self, action): action = np.clip(action, self.action_space.low, self.action_space.high) assert self.action_space.contains(action), action self._state = self._state + 0.1 * action reward = - np.linalg.norm(self._state - self._goal, ord=2) done = False ob = self._get_obs() info = {'task': self.get_task()} return ob, reward, done, info def close(self): self.close() pygame.quit() class SparsePointEnv(PointEnv): """ Reward is L2 distance given only within goal radius """ def __init__(self, goal_radius=0.2, max_episode_steps=100, goal_sampler='semi-circle', is_render=False): super().__init__(max_episode_steps=max_episode_steps, goal_sampler=goal_sampler, is_render=is_render) self.goal_radius = goal_radius self.reset_task() def sparsify_rewards(self, r): ''' zero out rewards when outside the goal radius ''' mask = (r >= -self.goal_radius).astype(np.float32) r = r * mask return r def reset_model(self): self._state = np.array([0, 0]) return self._get_obs() def step(self, action): ob, reward, done, d = super().step(action) sparse_reward = self.sparsify_rewards(reward) # make sparse rewards positive if reward >= -self.goal_radius: sparse_reward += 1 d.update({'sparse_reward': sparse_reward}) d.update({'dense_reward': reward}) return ob, sparse_reward, done, d def render(self, mode, tick): if mode=='text': print(f'State: {self._state}, Goal: {self._goal}') elif mode=='rgb': time.sleep(tick) goal_state = self.upscale(self._goal) agent_state = self.upscale(self._state) pygame.draw.circle(self.window, (0, 255, 0), goal_state, 4) pygame.draw.circle(self.window, (255, 0, 0) , agent_state, 4) pygame.display.update() def reset(self): obs = self.reset_model() if self.is_render==True: background_color=(255, 255, 255) self.window.fill(background_color) pygame.display.update() goal_state = self.upscale(self._goal) agent_state = self.upscale(obs) pygame.draw.circle(self.window, (0, 255, 0), goal_state, 4) pygame.draw.circle(self.window, (0, 0, 128), goal_state, self.goal_radius*(self.width/2)) pygame.draw.circle(self.window, (255, 0, 0) , agent_state, 4) pygame.display.update() return obs# policy_execution.py
import logging logger = logging.getLogger() logger.setLevel(logging.INFO) formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') import pygame import argparse parser = argparse.ArgumentParser() parser.add_argument('--state_dim', default=2) parser.add_argument('--linear_dim', default=128) parser.add_argument('--hidden_dim', default=64) parser.add_argument('--num_rnn_layers', default=2) parser.add_argument('--action_dim', default=2) parser.add_argument('--batch_size', default=16) parser.add_argument('--device', default='cpu') parser.add_argument('--is_continuous', default=True) args = parser.parse_args() from point_env import * from rnn_policy import RNNPolicy goal = semi_circle_goal_sampler() logger.debug(goal) rnn_policy = RNNPolicy(args) env = SparsePointEnv(goal_radius=0.5, max_episode_steps=100, goal_sampler='semi-circle', is_render=True) for e in range(10): done = False obs = env.reset() step = 0 while not done and step < env._max_episode_steps: env.render(mode='rgb', tick=0.1) env.render(mode='text', tick=None) action, log_prob = rnn_policy.choose_action(obs) next_obs, reward, done, info = env.step(action) step += 1
다음 포스팅에서는 RolloutBuffer와 Loss Function의 Update를 살펴볼 예정이다.
'Reinforcement Learning' 카테고리의 다른 글